Project Reactor: Guía Práctica de Programación Reactiva en Java
De la contrapresión a los virtual threads, Mono/Flux y el event loop — todo lo que aprendí construyendo sistemas de pago reactivos en BBVA, con los errores corregidos.
Project Reactor: Guía Práctica de Programación Reactiva en Java
Después de años construyendo sistemas de pago cloud-native en BBVA con Spring WebFlux, fui apuntando todo lo que aprendía sobre Project Reactor. Este post es una versión refinada de esos apuntes — con las imprecisiones corregidas.
¿Qué es Project Reactor?
Project Reactor es una librería de programación reactiva para Java que sirve como base de Spring WebFlux. Permite el procesamiento de datos asíncrono y no bloqueante mediante streams (Mono y Flux) con soporte de contrapresión.
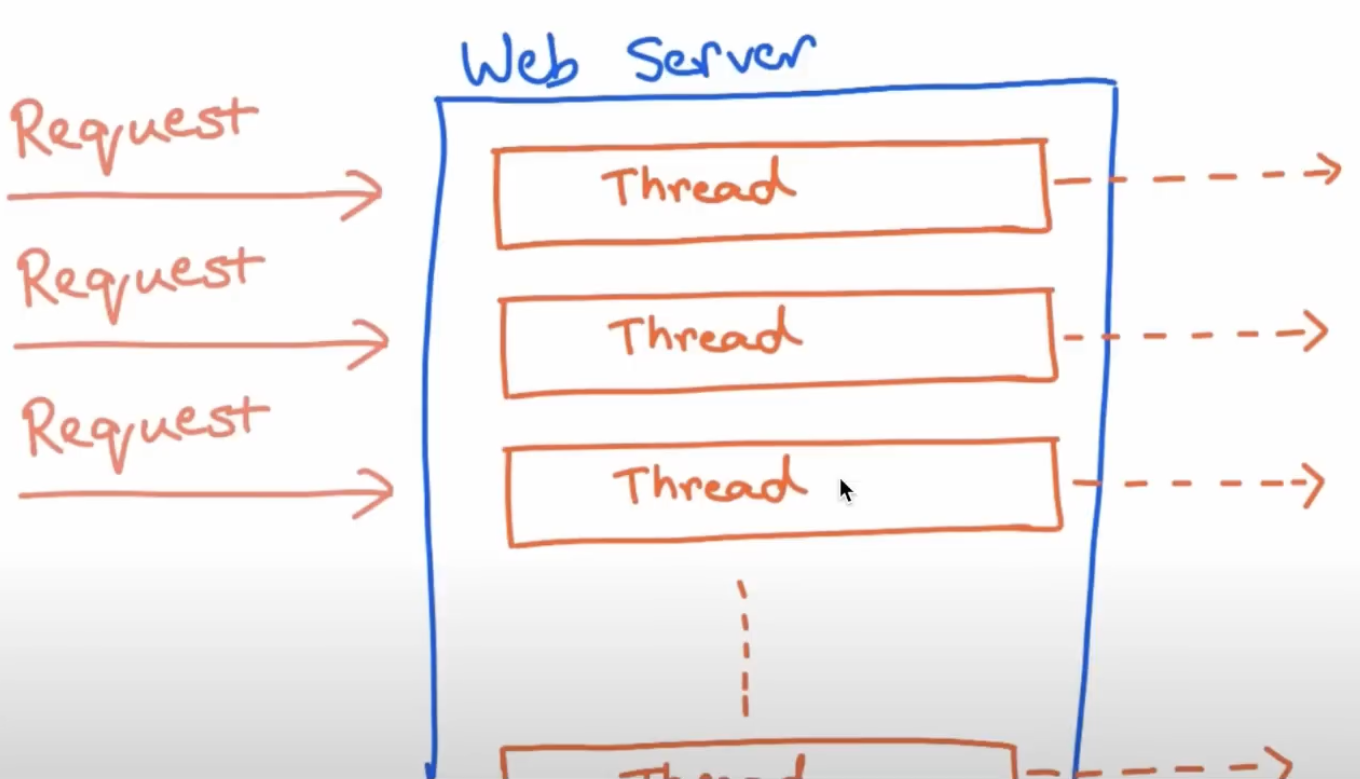
El problema que resuelve: en un stack tradicional de Spring MVC, cada petición ocupa un hilo hasta que termina. Con alta carga, te quedas sin hilos. Reactor permite que un número pequeño y fijo de hilos gestione miles de peticiones concurrentes sin bloquearse nunca.
El Problema del Código Bloqueante
Un endpoint bloqueante típico:
@GetMapping("/users/{userId}")
public User getUserDetails(@PathVariable String userId) {
User user = userService.getUser(userId);
UserPreferences prefs = userPreferencesService.getPreferences(userId);
user.setPreferences(prefs);
return user;
}Las dos llamadas son innecesariamente secuenciales. Mientras la primera espera respuesta, el hilo está parado sin hacer nada:
La solución reactiva:
@GetMapping("/users/{userId}")
public Mono<User> getUserDetails(@PathVariable String userId) {
return userService.getUser(userId)
.zipWith(userPreferencesService.getPreferences(userId))
.map(tuple -> {
User user = tuple.getT1();
user.setPreferences(tuple.getT2());
return user;
});
}No bloqueante, ambas llamadas en paralelo, y el pipeline es declarativo.
¿Qué es la Contrapresión?
La contrapresión es un mecanismo de control de flujo que evita que un productor rápido desborde a un consumidor lento. El consumidor señaliza cuántos datos puede manejar, y el productor respeta ese límite.
Es como un grifo que ajusta el caudal de agua en función de la rapidez con la que puedes llenar tu vaso.
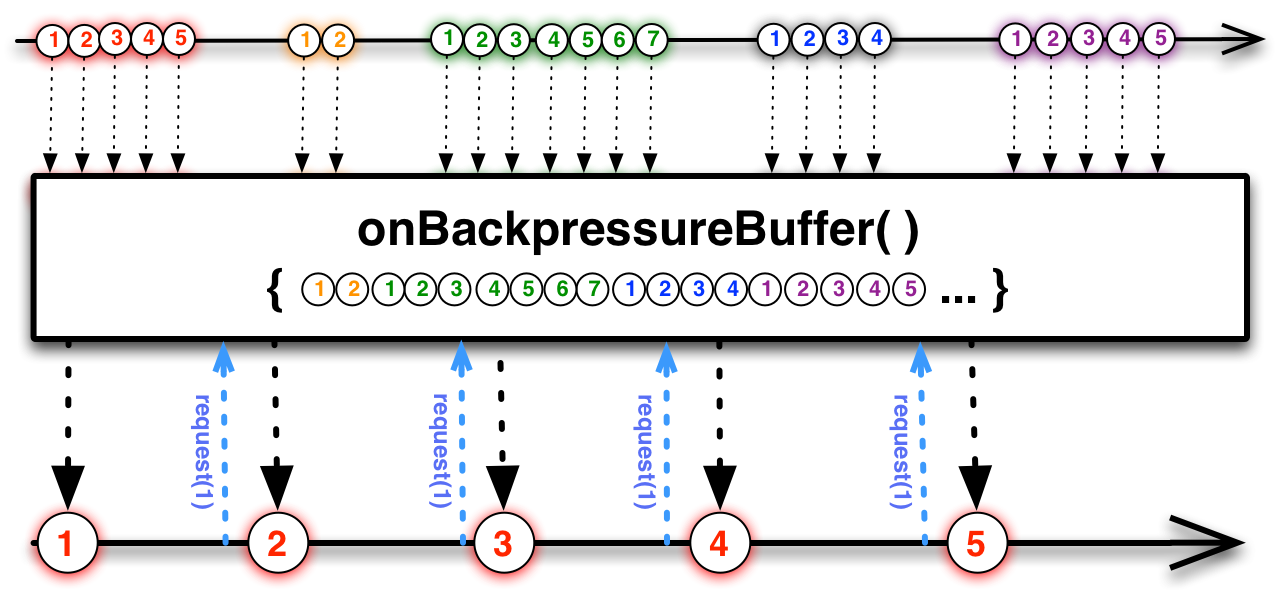
En la práctica: si tienes un Flux emitiendo 10.000 eventos por segundo pero tu base de datos solo gestiona 500 escrituras por segundo, la contrapresión evita quedarse sin memoria. El suscriptor solicita solo lo que puede procesar:
class MySubscriber<T> extends BaseSubscriber<T> {
@Override
public void hookOnSubscribe(Subscription subscription) {
request(2); // pide solo 2 elementos a la vez
}
@Override
public void hookOnNext(T value) {
System.out.println("Recibido: " + value);
request(2); // pide 2 más al terminar
}
}El Manifiesto Reactivo
Project Reactor está construido sobre el Manifiesto Reactivo:
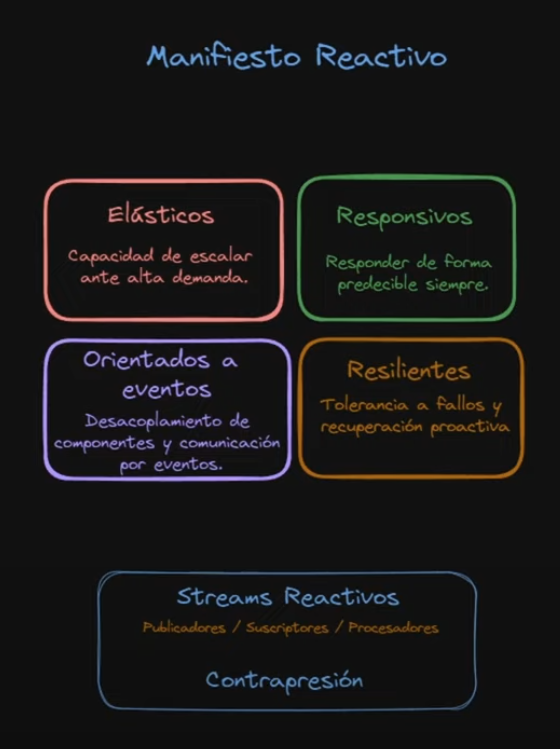
- Responsivos — responden de forma predecible en todas las condiciones
- Resilientes — tolerantes a fallos, con recuperación proactiva
- Elásticos — escalan hacia arriba y hacia abajo según la demanda
- Orientados a mensajes — los componentes se comunican mediante paso de mensajes asíncronos con destinatarios explícitos
El cuarto pilar es “Message Driven” (orientado a mensajes), no “orientado a eventos”. La diferencia importa: orientado a mensajes implica destinatarios explícitos y transparencia de ubicación.
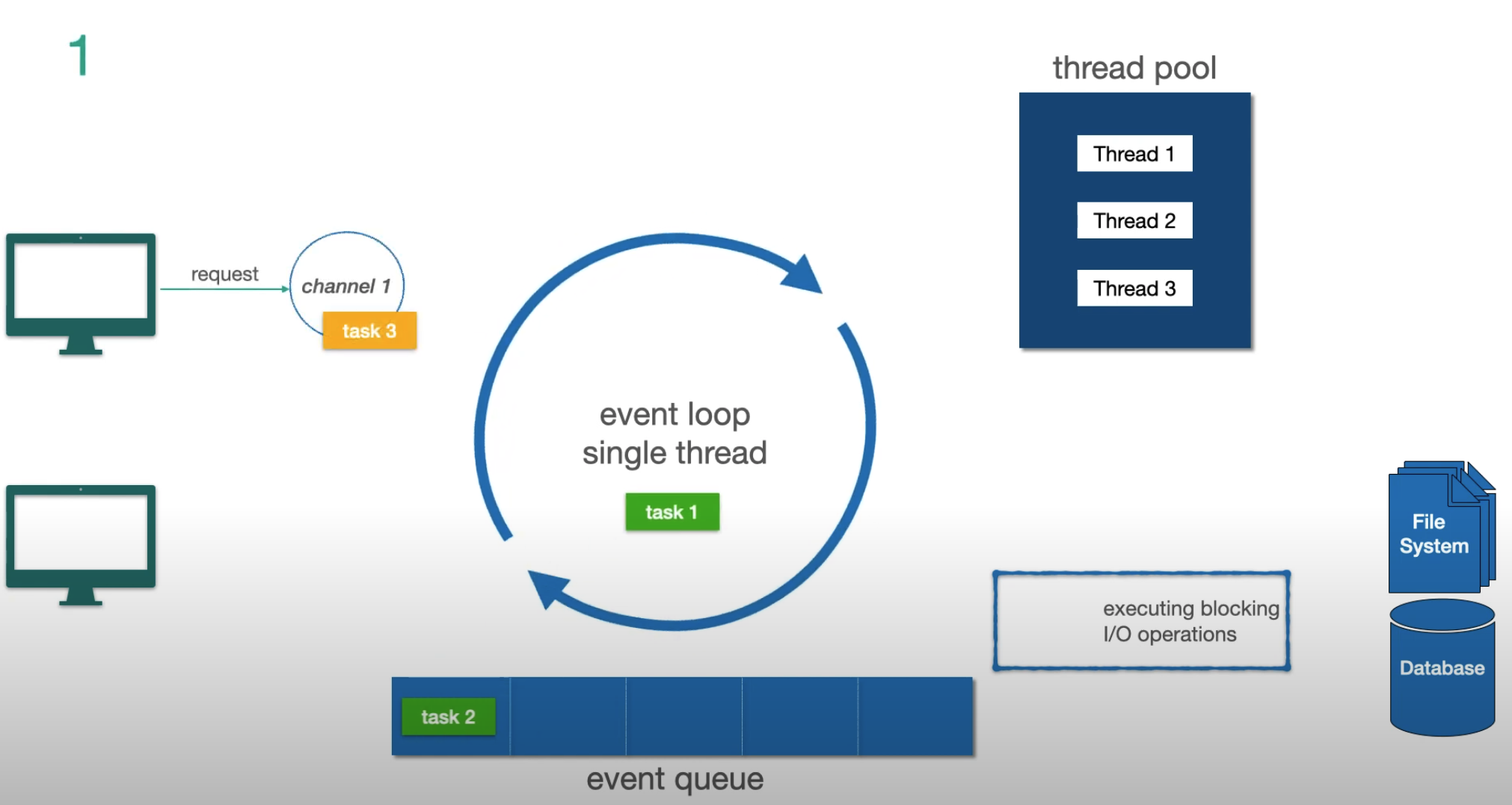
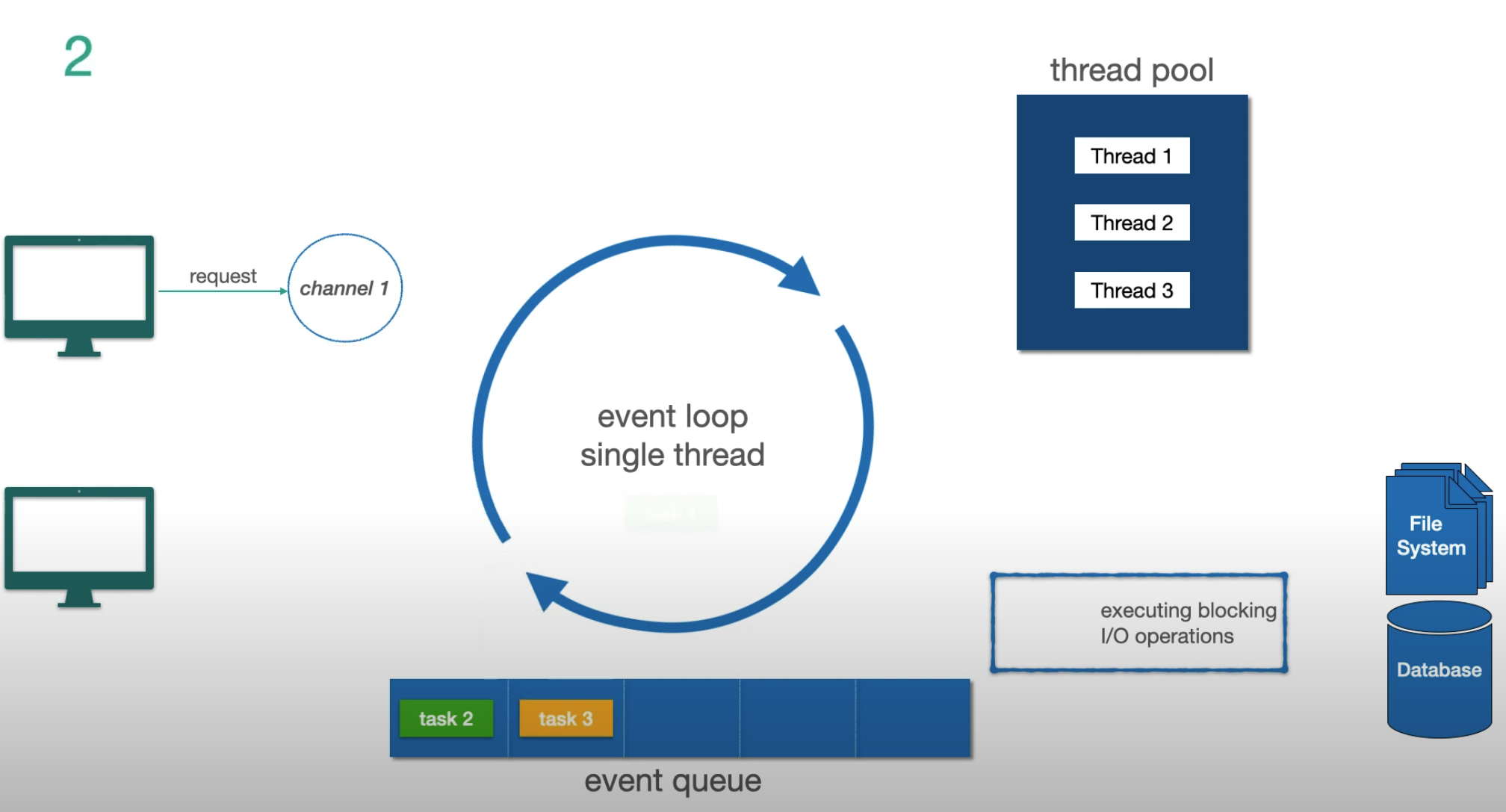
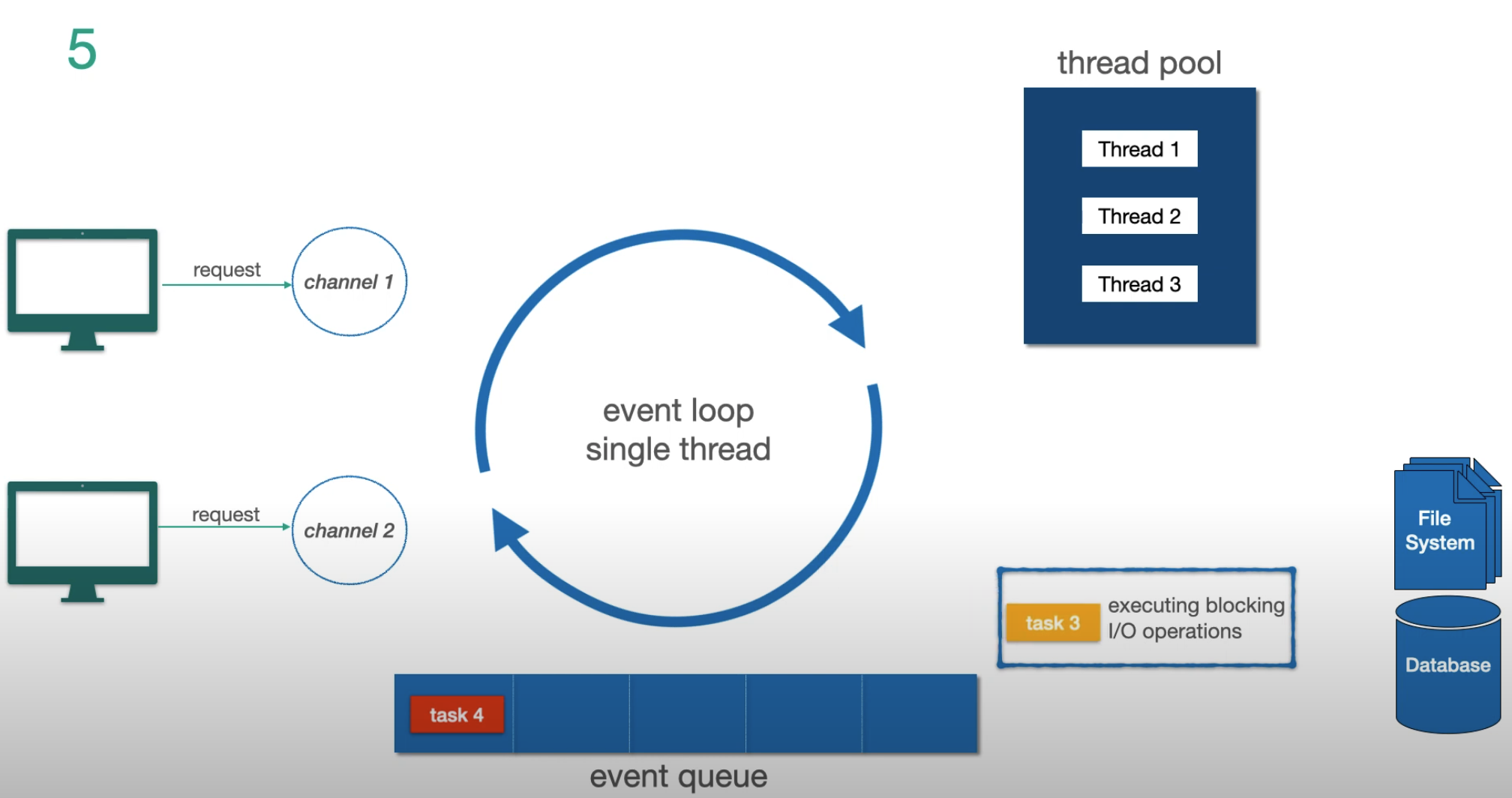
El Modelo Event Loop
El mecanismo fundamental detrás de Reactor y Netty (el servidor por defecto de WebFlux):
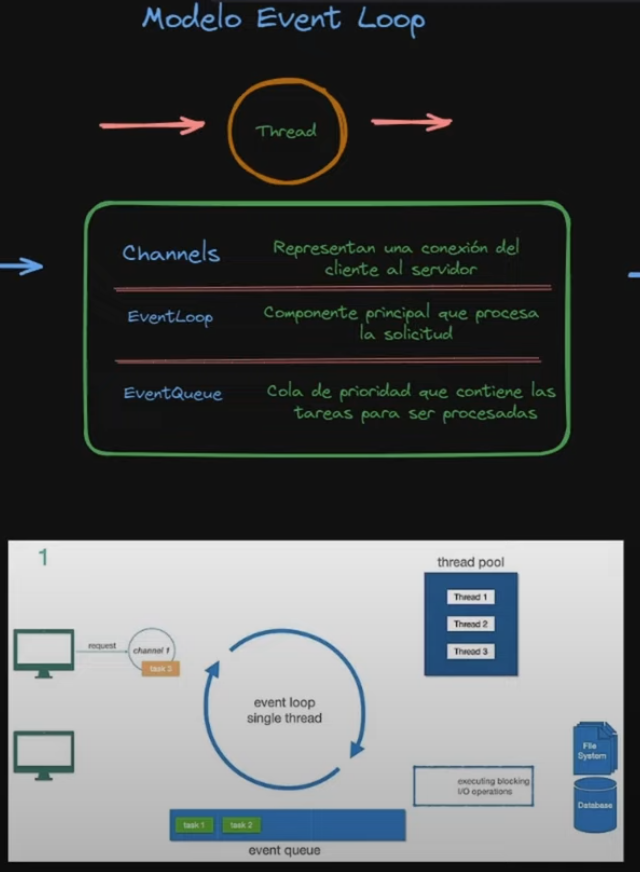
Tres conceptos clave:
- Channel — representa la conexión del cliente al servidor
- Event Loop — el hilo único que procesa tareas. Un event loop por núcleo de CPU
- Event Queue — cola FIFO de tareas (no una cola de prioridad)
La regla crítica: el event loop nunca se bloquea. Cuando detecta una operación I/O bloqueante, la delega al thread pool y pasa inmediatamente a la siguiente tarea. Cuando el I/O termina, el resultado vuelve como un nuevo evento.
Veamos un ejemplo paso a paso:
Paso 1 — dos tareas no-I/O en cola, llega una nueva petición:
Paso 2 — llega otra petición, se encola como tarea 4:
Paso 3 — la tarea 3 es I/O bloqueante, se delega al thread pool:
Paso 4 — mientras la tarea 3 corre en paralelo, el event loop responde a la tarea 4:
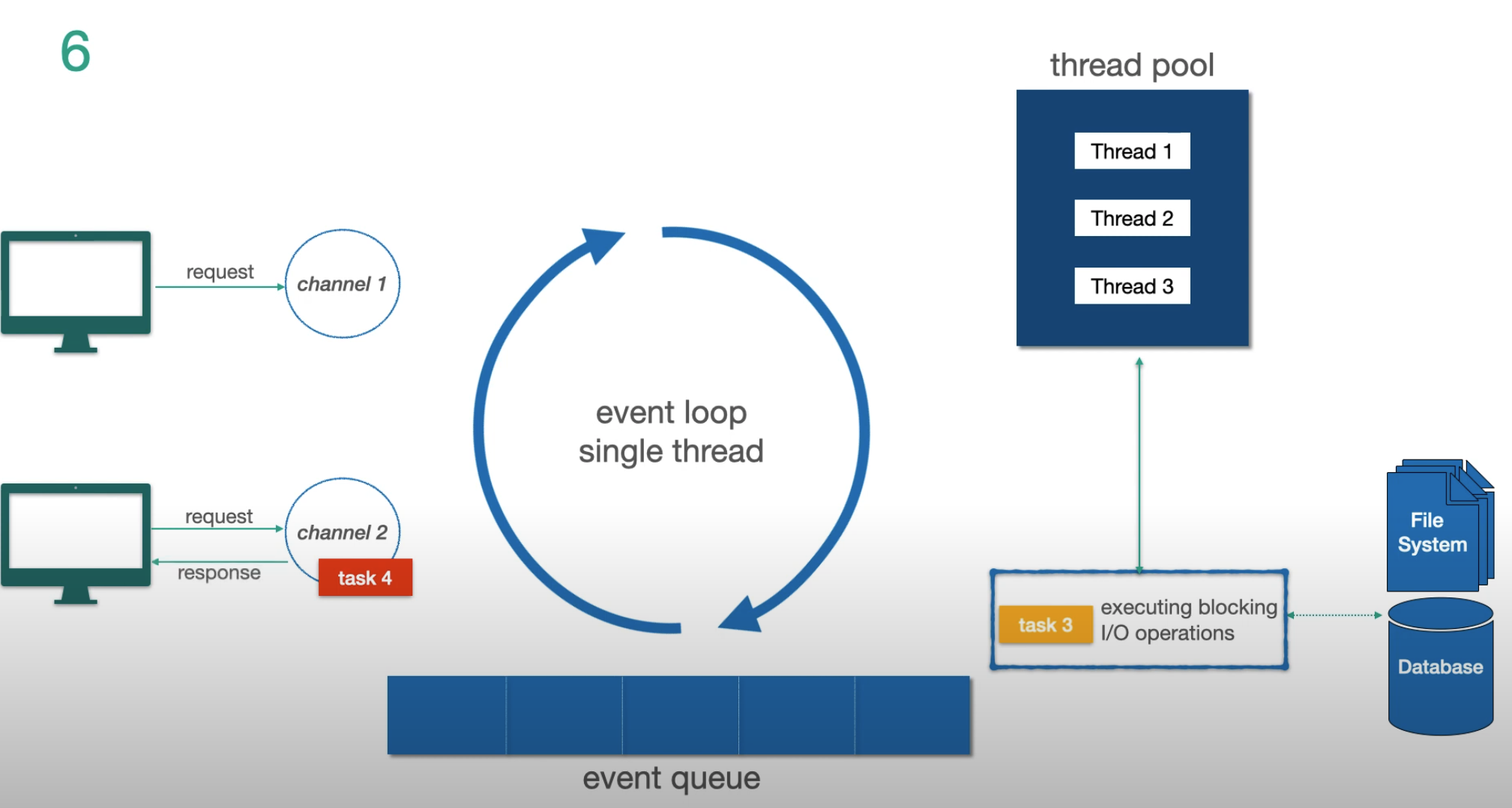
Paso 5 — la tarea 3 termina su I/O y vuelve al event loop para completarse:
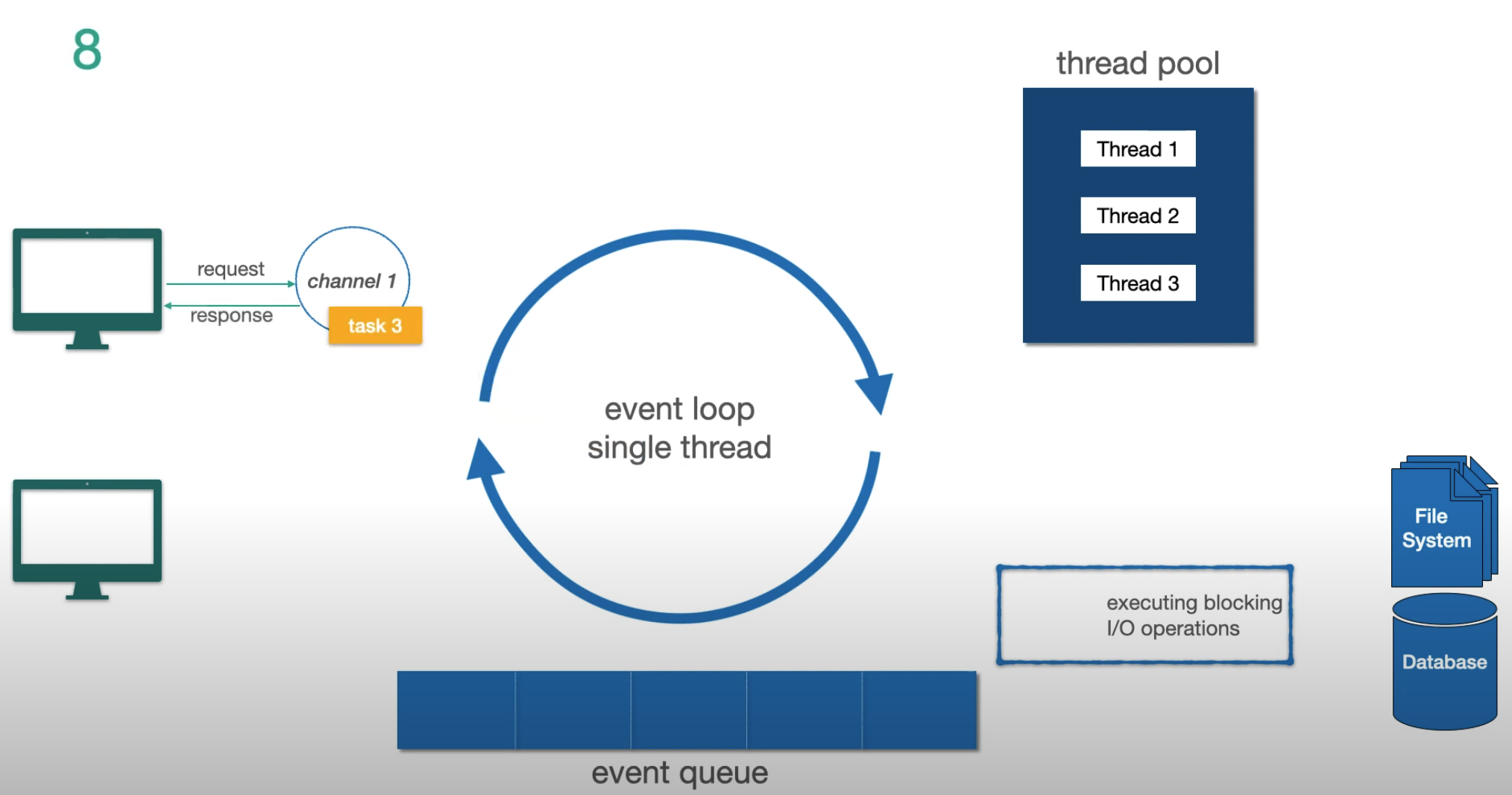
Conclusiones clave:
- El event loop nunca espera por I/O
- Las operaciones I/O van al thread pool; las no-I/O se ejecutan directamente en el event loop
- En Netty, los hilos del event loop aparecen como
reactor-http-nio-1,reactor-http-nio-2, etc.
Cómo lo Usa Spring WebFlux

Spring WebFlux se asienta sobre Netty y Project Reactor. El Flux fluye desde el repositorio de datos hasta el servidor HTTP, con escrituras no bloqueantes y contrapresión hasta el socket.
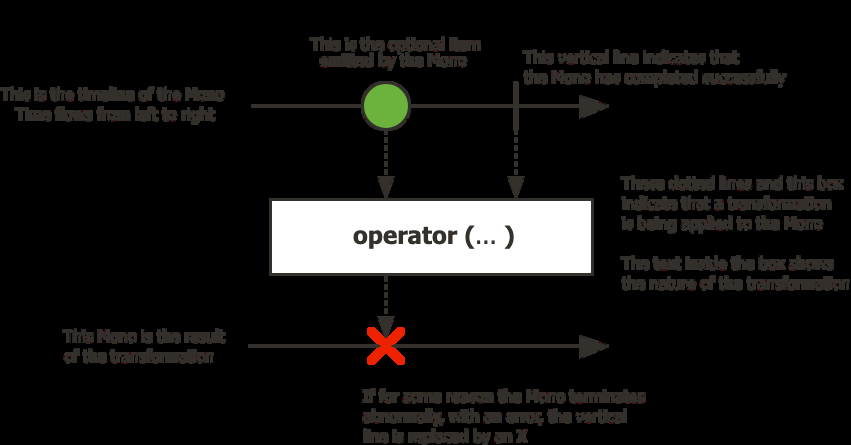
Mono y Flux — Leer Diagramas de Mármol
Mono<T> — stream de 0 o 1 elemento:
Flux<T> — stream de 0 a N elementos:
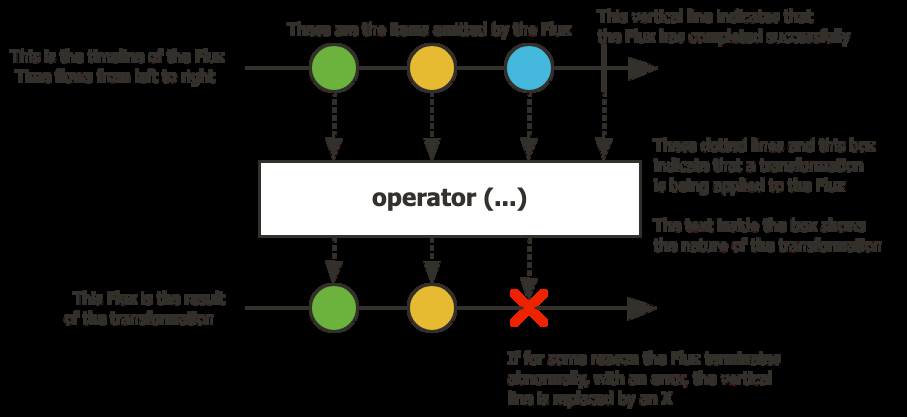
Cómo leerlos: el tiempo fluye de izquierda a derecha. Cada círculo es un ítem. La línea vertical es la señal de completado. Una X significa error (terminal). La caja es el operador aplicado.
Un Flux puede emitir:
- Cualquier número de ítems (en el orden en que son producidos)
- Un evento de completado — terminal, nada más llegará después
- Un evento de fallo — terminal, nada más llegará después
Los eventos terminales siempre son los últimos. Nunca recibirás un ítem después de un evento terminal.
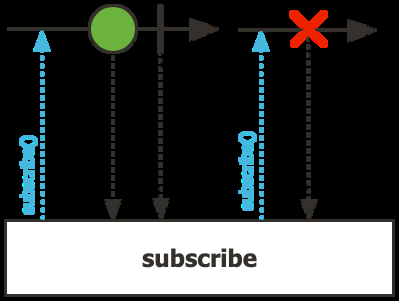
Nada Ocurre Hasta Que Suscribes
Un Mono o Flux es lazy — describe un pipeline, pero nada se ejecuta hasta que alguien suscribe.
Disposable subscribe = ReactiveSources
.intNumbersFlux()
.subscribe(
number -> System.out.println(number),
err -> System.out.println(err),
() -> System.out.println("Completado")
);subscribe() devuelve un Disposable — llama a dispose() para cancelar. Es idempotente.
La API de Reactor usa el patrón Fluent Interface — cada operador devuelve un nuevo Mono o Flux, permitiendo encadenar operaciones en un pipeline legible:
flux.filter(element -> element != null)
.map(element -> element.toUpperCase())
.flatMap(element -> externalService.enrich(element))
.subscribe(element -> System.out.println(element));Distinción clave entre operadores:
map— síncrono, uno a unoflatMap— asíncrono, orden no determinista (usaconcatMappara conservar el orden)doOnNext/doOnError— hooks de efectos secundarios, no transforman el stream
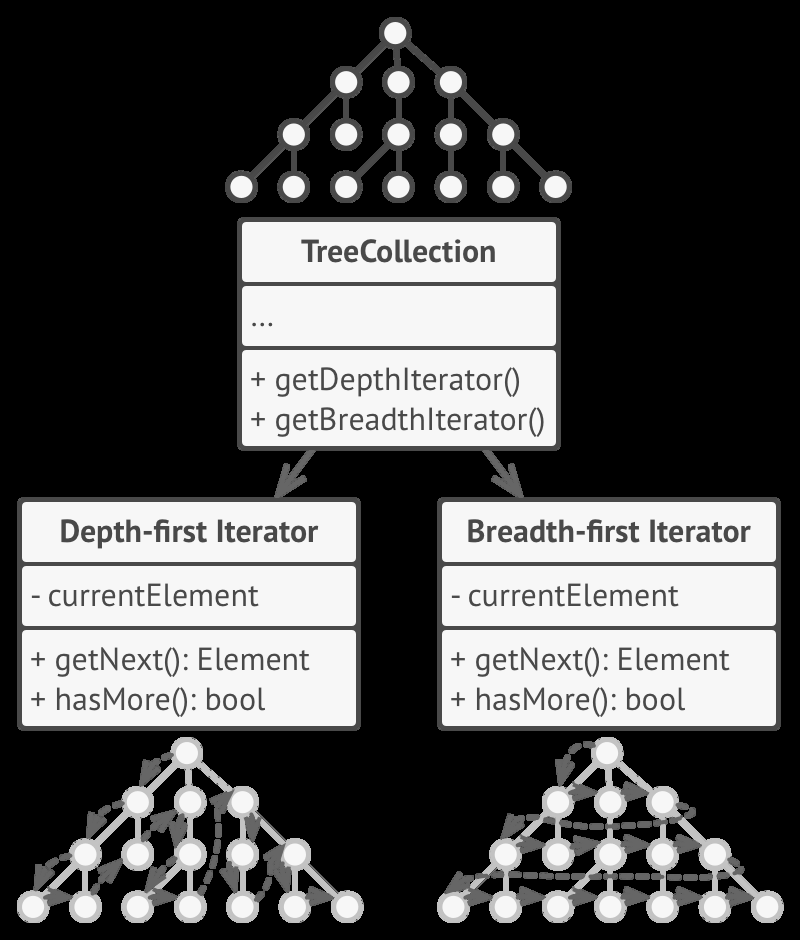
El Origen: Iterator + Observer
La programación reactiva es la combinación de dos patrones de diseño clásicos.
Iterator — el consumidor extrae datos de una colección:
Observer — el productor empuja datos a los suscriptores:
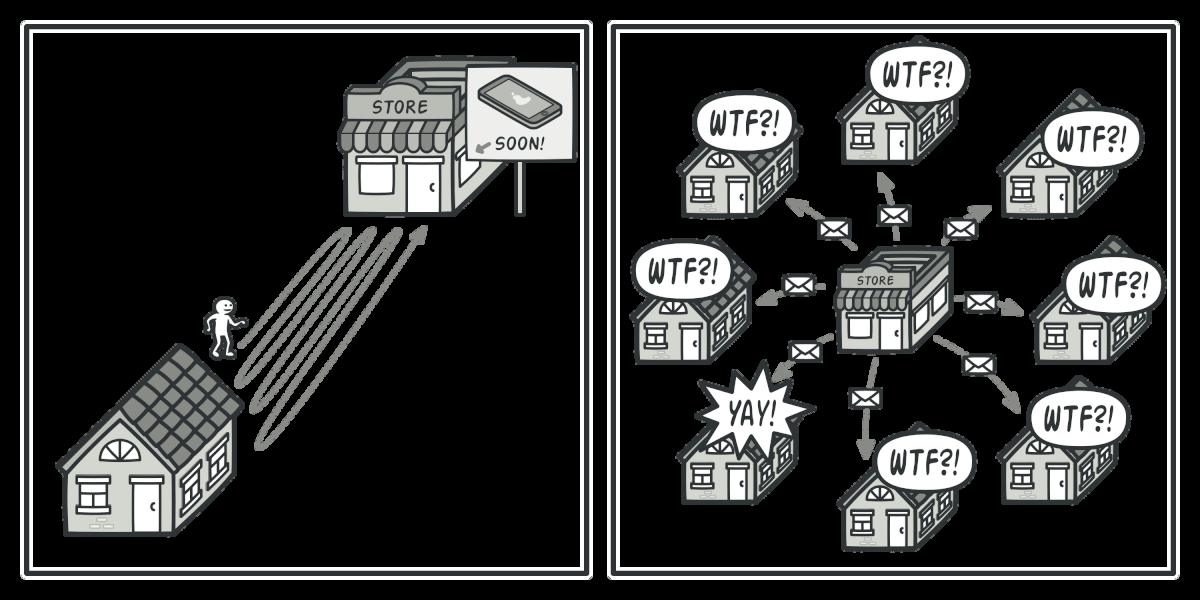
La relación entre ambos:
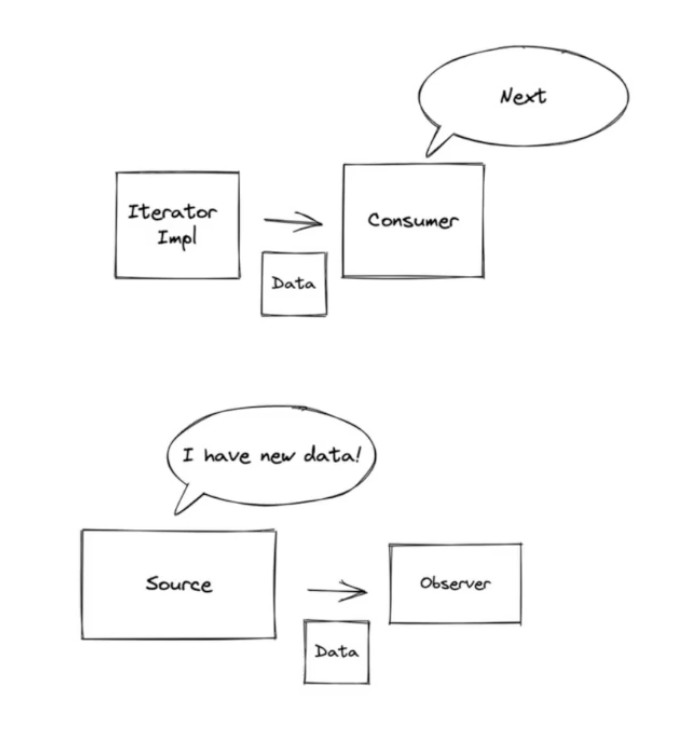
// Iterator — tú controlas cuándo tirar
myList.forEach(element -> System.out.println(element));
// Observer — los datos se empujan cuando están disponibles
clicksChannel.addObserver(event -> System.out.println(event));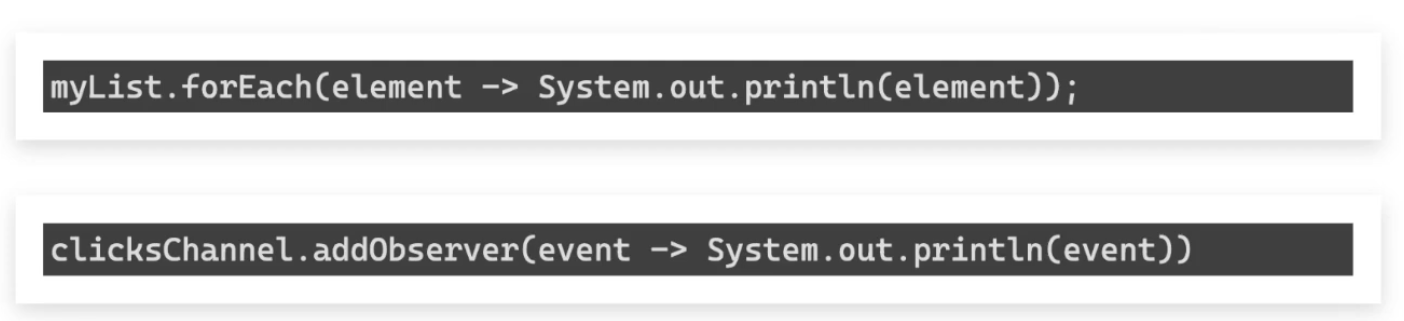
La programación reactiva invierte el Iterator: en lugar de que el consumidor tire, el productor empuja. Luego añade contrapresión para que el consumidor pueda señalizar cuánto puede manejar. Esta combinación — más la composición de operadores en cadena — es el momento del “click”.
Reactor vs Virtual Threads
Java 21 introdujo los virtual threads (Project Loom) como alternativa.
Cómo funcionan los virtual threads:
1. El hilo arranca en un carrier thread:
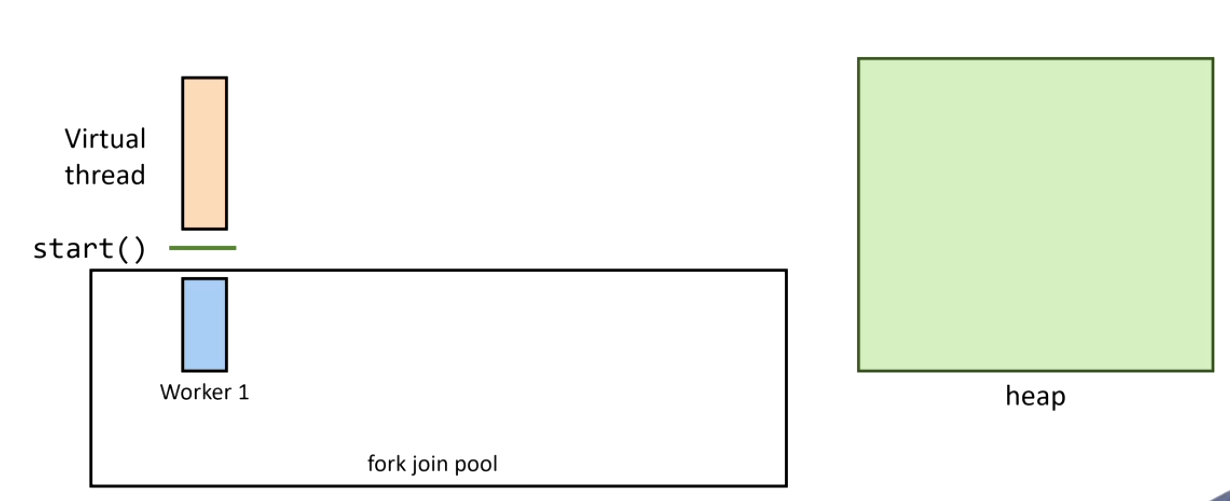
2. Se realiza una llamada bloqueante — se llama a Continuation.yield():
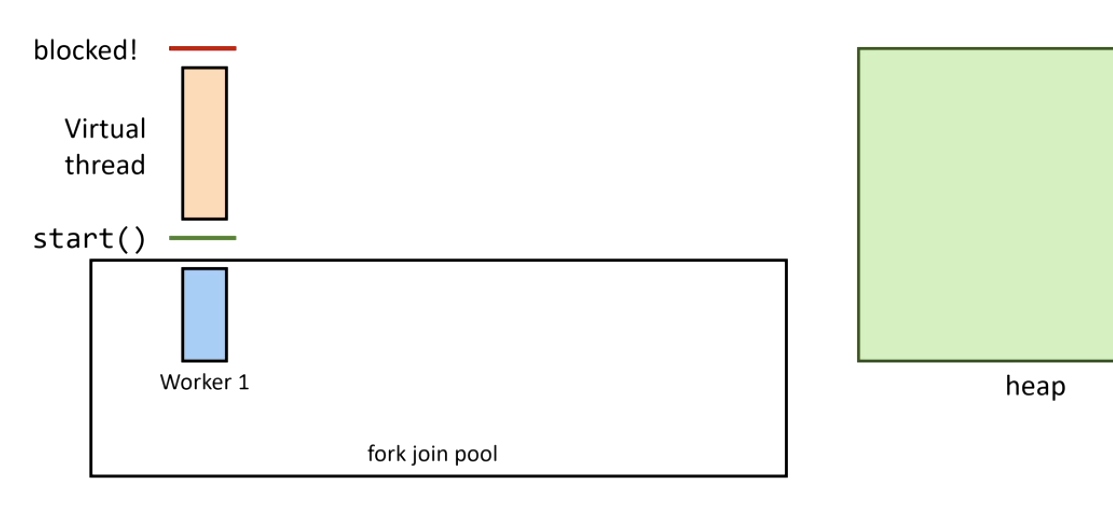
3. El virtual thread se desmonta y su stack se copia a heap:
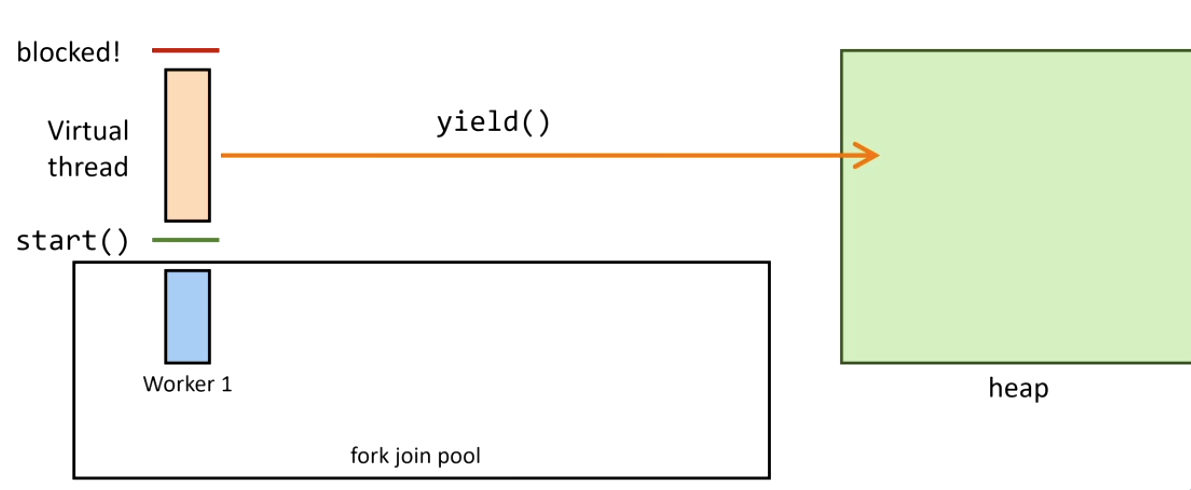
4. La operación bloqueante termina — Continuation.run() remonta el virtual thread:
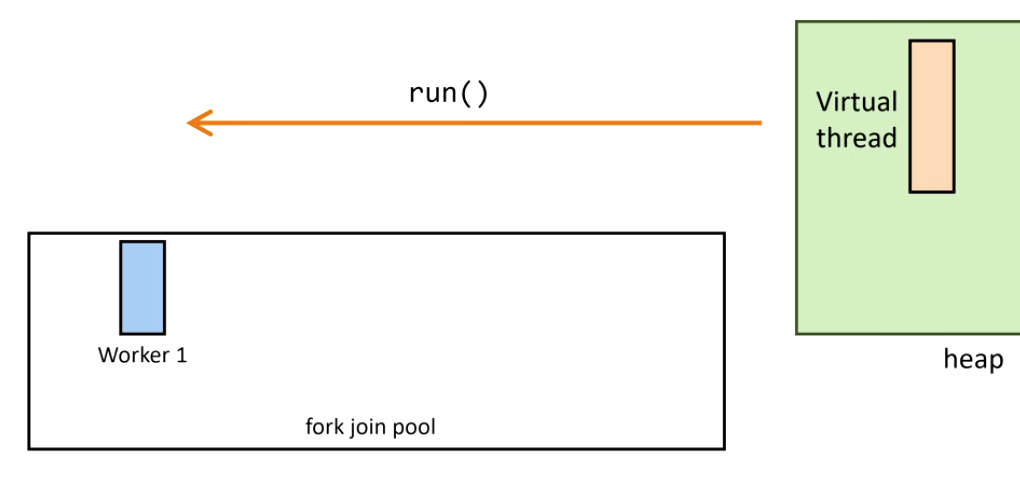
5. Si el carrier original está ocupado, otro hilo roba la tarea (work stealing del ForkJoinPool):
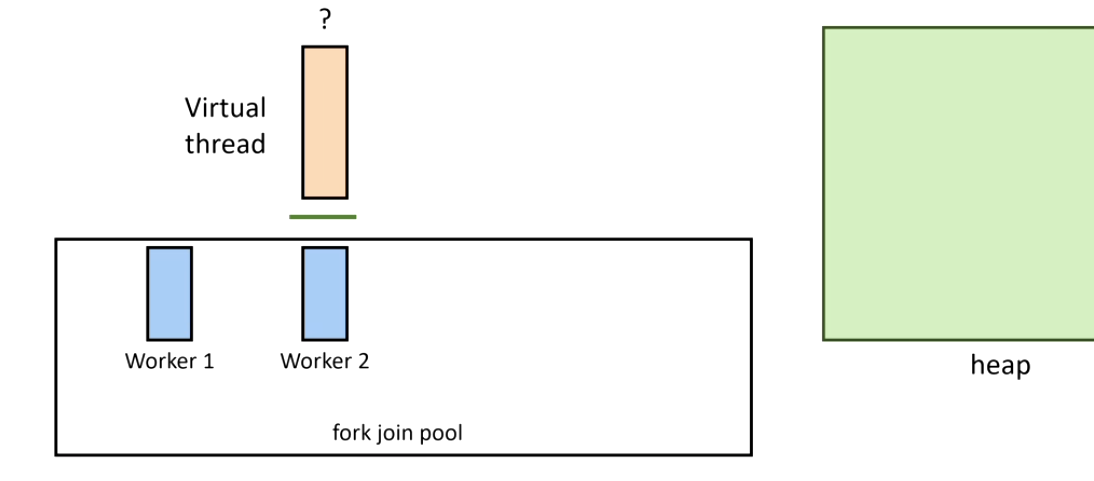
Corrección importante sobre el coste de creación: los virtual threads son más baratos de crear que los platform threads, no más caros. Un platform thread mapea a un hilo del SO con un stack fijo de ~1MB — una llamada al sistema costosa. Un virtual thread es un objeto JVM ligero con un stack dinámico pequeño en heap. Puedes crear millones de ellos.
| Project Reactor | Virtual Threads | |
|---|---|---|
| Modelo de programación | Pipeline funcional | Imperativo (parece síncrono) |
| Curva de aprendizaje | Pronunciada | Baja |
| Contrapresión | Nativa | Manual |
| Mejor para | I/O de alta concurrencia, streaming | Simplificar código bloqueante |
Usa virtual threads para: envolver APIs bloqueantes existentes de forma más sencilla.
Usa Reactor para: nuevos sistemas de alto throughput donde la contrapresión y la composición de pipelines importan.
¿Cuándo Ir Reactivo?
Ve reactivo si:
- Tu aplicación es intensiva en I/O (APIs, llamadas a BD, streaming)
- Necesitas control de contrapresión nativo
- Estás construyendo un nuevo servicio sobre Spring WebFlux desde cero
Ten cuidado si:
- Las tareas CPU-bound dominan → el cómputo bloqueante paraliza el event loop. Solución:
publishOn(Schedulers.parallel()) - Integras con librerías bloqueantes →
Mono.fromCallable()+Schedulers.boundedElastic() - El equipo no conoce el paradigma — la curva de aprendizaje tiene un coste real
Regla de oro: ve reactivo hasta el final, o no vayas reactivo en absoluto. Mezclar código bloqueante y no bloqueante en el mismo pipeline es lo peor de los dos mundos.